자료구조> 기본
배열 데이터를 나열한다. 각 데이터를 인덱스에 대응한다. 파이썬에선 리스트가 배열을 담당한다. 같은 종류를 효율적으로 관리 같은 종류를 순차적으로 저장 빠른 접근 추가/삭제가 쉽지 않다.
seol2.tistory.com
CS> Array List 와 Linked List의 차이점?? (tistory.com)
CS> Array List 와 Linked List의 차이점??
Interface supports an ordered sequence of elements Vector, ArrayList, LinkedList Vector 처음부터 만들어져서 지금까지 유지되어 온 리스트 계열의 컬렉션 특별히 크기를 지정하지 않을 경우 사이즈를 늘..
seol2.tistory.com
다른 글에서 정리를 한 번 했지만 까먹었으니 복습.
기타 다른 자료구조 설명은 다른 블로그에서 보자
Java - Collection과 Map의 종류(List, Set, Map) (tistory.com)
Java - Collection과 Map의 종류(List, Set, Map)
Collection과 Map Java의 자료구조는 크게 Collection과 Map으로 나눌 수 있음 그리고, Collection은 List와 Set, Queue로 나눌 수 있음 본 글에서는 아래 자료구조에 대한 내용을 간단히 정리한다. List : Array..
memostack.tistory.com
여기서 볼 것


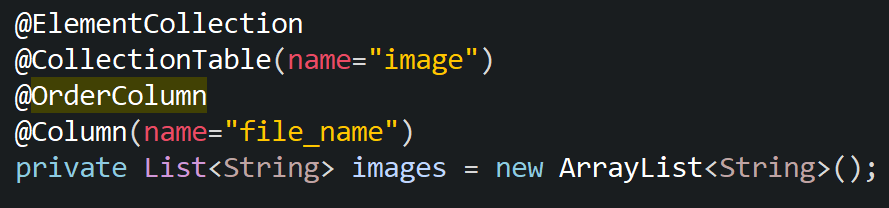
@ElementCollection
: Hibernate에게 collection을 mapping한다고 말한다.
@CollectionTable
: Collection 테이블 이름 명시
join할 Column이름을 쓴다.

@ElementCollection은 관계 정의하기 위해 사용.
One to many 관계를 할 수 있는 객체는
@Embeddable 붙이는 객체 또는
Java primitives(wrappers) - int, Integer, Double, 등등 이나
Date, String 등등 의 기본 객체이다.
복습하자
CS> autoboxing 과 unboxing은 무엇인가? (tistory.com)
CS> autoboxing 과 unboxing은 무엇인가?
자바에는 크게 두 가지 데이터 타입이 있다. Primitive Data 와 Wrapper Class 이다. 여기서 잠깐 Primitive data를 복습하자.. primitive Type 기본형 타입이다. 기본값이 있기 때문에 Null은 존재하지 않는다...
seol2.tistory.com
그렇다면 @OneToMany와 @ElementCollection은 무슨 차이점이 있을까?
둘이 비슷하지만
@ElementCollection은 @Entity가 아닌 객체를 잡을 수 있다는 것이다.
예를 들어 위에서 사용한
private Set<String> images = new HashSet<String>( );
HashSet 객체를 oneToMany할 수 있다.
그러나 단점이 있다.
Cascade option을 주지 못한다.
언제나 부모 객체에 persist, merge, remove 된다.
@ElementCollection은 간단한 객체를 collection으로 사용할 때 쓰면 좋다.
@OneToMany는 복잡하게 사용할 때 쓰자.

메이븐 프로젝트 하나 간단하게 만들어주자.

pom.xml에서 dependencies 지워주고
properties에서 버전을 11로 바꾼다.
<!-- Hibernate's core ORM functionality -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.3.6.Final</version>
</dependency>
<!-- JDBC driver for MySQL -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
</dependency>
<!-- Support for Java 9/10/11 -->
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-core</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>com.sun.activation</groupId>
<artifactId>javax.activation</artifactId>
<version>1.2.0</version>
</dependency>
dependency 붙인다.

hibernate.cfg.xml에 데이터베이스 url과 username/password를 넣는다.
이제 MySQL workbench 틀자
connection 로그인해서 들어가서
CREATE DATABASE IF NOT EXISTS `[여기에 스키마 이름]`;
USE `[여기에 스키마 이름]`;
DROP TABLE IF EXISTS `[여기에 테이블 이름]`;
CREATE TABLE `[여기에 테이블 이름]` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) DEFAULT NULL,
`last_name` varchar(45) DEFAULT NULL,
`email` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=101 DEFAULT CHARSET=latin1;
DROP TABLE IF EXISTS `[여기에 테이블 이름2]`;
CREATE TABLE `[여기에 테이블 이름2]` (
`student_id` int(11) NOT NULL,
`file_name` varchar(45) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;스크립트 작성해서 스키마와 테이블 생성
다시 이클립스로 고고

패키지 만들고 클래스 만들고
만약에 src/cmain/resources가 없으면
프로젝트 오른쪽 버튼 누르고 source 탭에서 add folder 버튼을 누른다.
그리고 resources 폴더를 체크한다. 오케이 누르고 apply 적용 ㄱㄱ

필드 생성

필드 위에 annotation 작성
getter/setter
toString
Constructor using field
메서드를 생성한다.

id는 빼고 한다.
hibernate가 다루게 냅둔다.


세션팩토리 만들기
세션 만들기
객체 생성
트랜잭션 시작
객체 저장
트랜잭션 커밋
마무리



sql를 작성하여 테이블을 만들 필요없이 java 코드에 작성하면 hibernate가 이걸 바탕으로 테이블을 만든다.

테이블을 drop하고 만든다.
| Property Value | Property Description |
| none | 아무것도 안한다. |
| create-only | 데이터베이스 테이블이 생성된다. |
| drop | 데이터베이스 테이블이 삭제 |
| create | 데이터베이스 테이블이 삭제되고 생성된다. |
| create-drop | 세선팩토리가 시작할 때 데이터베이스 테이블을 삭제하고 재생성한다. 세션팩토리가 꺼지면 테이블을 삭제한다. |
| validate | 데이터베이스 테이블 스키마를 확인한다. |
| update | 데이터베이스 테이블 스키마를 업데이트한다. |
이 기능은 데이터가 삭제되니 테스트할 때 사용하고 실제는 sql을 사용하자
이 기능을 사용하는 이유는 테스트할 때 번거롭지 않고 편하게 테스트하기 위해서




@OrderColumn
순서값을 저장하는 칼럼이 만들어진다.
[이름]_ORDER 이름으로 칼럼이 만들어진다.

'컴퓨터공학 > Hibernate' 카테고리의 다른 글
| Hibernate> Inheritance Mapping> Joined Tables and Mapped Superclass (0) | 2021.12.04 |
|---|---|
| Hibernate> Inheritance Mapping> Table Per Class (0) | 2021.12.04 |
| Hibernate> Inheritance Mapping> Single Table Strategy (0) | 2021.12.04 |
| Hibernate> Mapping Components Embeddable and Enums (0) | 2021.11.20 |
| Hibernate> Mapping Collection> Map, Sorted Set, Sorted Map (0) | 2021.11.20 |



